

高维空间:AI语义世界的隐藏结构
在人工智能的语义世界里,有一个神秘又强大的领域:高维空间(High-dimensional space)。它是理解大模型、潜在语义、生成文本甚至图像创作的关键。然而,“高维”听起来总是让人有些陌生:我们活在三维世界,那 AI 的“几百维”世界到底是怎么回事?
本文将带你揭开高维空间的面纱,从直观感受出发,深入理解它如何构建起今天 AI 的核心认知结构。
什么是“维度”?从1维到768维
我们熟悉的世界是三维的:长、宽、高。
而在数据世界,每一个变量或特征都是一个“维度”。
一张图片可以有上千个像素点 → 每个像素都是一个维度;
一句话可以被编码成一个向量,比如 GPT 把它转成 768维,每一维代表一句话在“语义、语法、上下文”等方面的抽象信息。
你可以这样理解:
一维是线,二维是面,三维是空间,高维是抽象的信息空间。
说明: GPT-2 模型中,每个词会被转成一个 768维的向量,这是模型结构决定的,主要为了兼顾计算效率和语义表达力。
为什么 AI 需要高维空间?
因为现实世界的信息太复杂了!
语义:同一个词有不同含义(如“bank”是银行还是河岸?);
上下文:AI 需要判断一段话的背景、情绪、意图;
多模态:文本、图像、声音需要融合处理。
高维空间就像一个语义宇宙,每个维度代表一个我们日常无法单独感知的特征。模型在这里做的事情,不再是“识别图片上有几只猫”,而是“理解这只猫在干什么,它的动作、颜色、表情、背景情境和它的语义关联”。
潜在空间(Latent Space):高维的核心舞台
在许多 AI 模型中,有一个关键阶段叫做“编码”:把输入的数据(如文本)转成一个隐藏的向量表示。这组向量所在的空间就是 潜在空间(latent space),通常是一个几十到上千维的高维空间。
举个例子:
“The cat is sleeping on the bed.”
→ 编码后得到一个 32维向量,像这样:
[0.12, -0.45, …, 0.88]
这个向量就代表了这句话的“语义指纹”,能被模型理解、比较、操作。
如果把多句话放进同一个潜在空间,我们会发现:
相似的句子(如关于猫、床、睡觉的句子)在空间中彼此靠近;
语义不同的句子(如“Birds are flying in the sky.”)会在空间的另一个方向。
这说明:高维空间不是混乱的,而是有结构的!
可视化:从高维到二维的降维操作
我们人类只能感知二维或三维的空间,所以为了看懂高维空间里的结构,我们会用一些“降维”技术,比如:
PCA(主成分分析):找到数据变化最大的两个维度,投影出来;
t-SNE:更关注数据之间的相对距离,适合看“聚类结构”。
下面这张图(示意)展示了六句话在 latent space 中的分布:
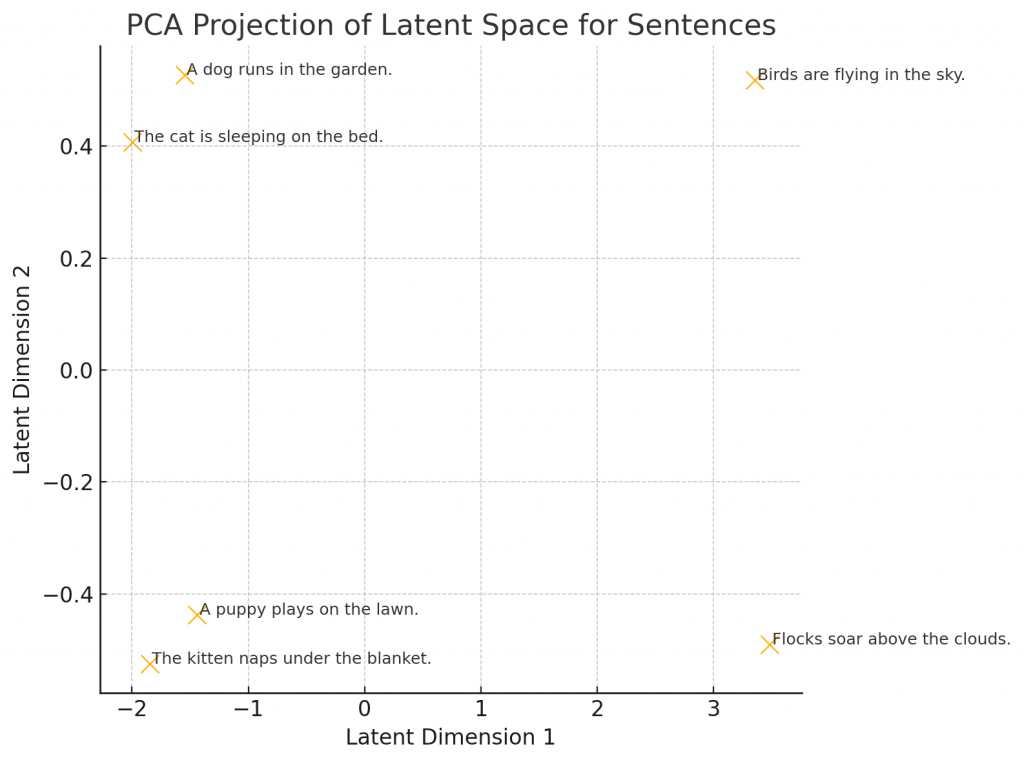
描述“猫”和“狗”的句子集中在左侧;
描述“飞鸟”的句子偏向右上角。
这说明模型在高维空间中,成功地把语义进行聚类和区分。
高维的力量与代价
高维空间带来的是表达力和抽象力,但也有挑战:
优点:可以编码复杂语义;容易在数学上把不同的概念区分开;支持文本生成、图像创作、多模态融合等高级能力。
缺点(也被称为“维度灾难”):数据在高维中变得稀疏,学习难度上升;计算资源消耗大;人类无法直接感知、解释高维空间中的变化。
总结:高维空间是 AI 的语义舞台
如果你把人工智能比作一个会思考的大脑,那高维空间就是它的思维剧场。句子、图像、声音都被转化为抽象的向量,在这个空间中互动、排列、演化,最终生成你在屏幕上看到的文字与画面。
高维不是虚构,而是我们对复杂世界的数学理解方式。
理解高维空间,也就理解了 AI 是如何“理解我们”。


