

认知跃迁:视觉推理如何重塑人工智能
当我们向AI展示一张图表,问它:“这里的趋势是否反常?”
过去,它只能描述线条的形状;现在,它可以分析因果、判断逻辑、提出假设。
这不只是看图识物,而是“图像中的思维”。
2025年4月,OpenAI 发布了一篇名为《Thinking with Images》的文章,介绍其最新发布的多模态模型 GPT-4o 如何实现“视觉推理(Visual Reasoning)”能力。这一进展不仅让大模型“看图说话”更流畅,更标志着人工智能进入了一个全新的认知阶段:思维不仅依赖语言,也开始与图像协同。
这意味着什么?视觉推理的本质是什么?它将如何影响我们理解 AI 的能力边界?这篇文章试图从技术、认知和未来图景三个维度,深入解读这一突破的意义。
理解图像中的关系
过去十年,计算机视觉领域取得了显著进展。AI 能够识别图像中的物体、检测人脸、识别场景,甚至生成图像。但这些能力大多属于“感知层”,即把像素信息转化为标签或描述——相当于“眼睛看见了什么”。
而视觉推理所提出的是一种更高层次的认知要求:
不仅看到图像中“有什么”,还要理解这些事物“为什么这样”、“如何联系”、“会发生什么”。
举例来说:
识别图像中有一张餐桌、两个人正在吃饭,这只是视觉识别;
如果问:“他们是在约会还是商务会谈?”模型需要结合服装、表情、桌上的物品等视觉细节进行情境推理——这就属于视觉推理。
识别图中有一个折线图,是视觉识别;
如果问:“图中哪一年增长率最高?是否存在异常波动?”模型需要理解图表结构、读取数值并结合整体趋势进行分析——这就是视觉推理。
识别一张手写数学题照片并读出‘x + 3 = 7’,是识别能力;
如果模型进一步计算出 x = 4,甚至指出可能的笔误或推理过程,那就是整合语言理解与逻辑演算的视觉推理。
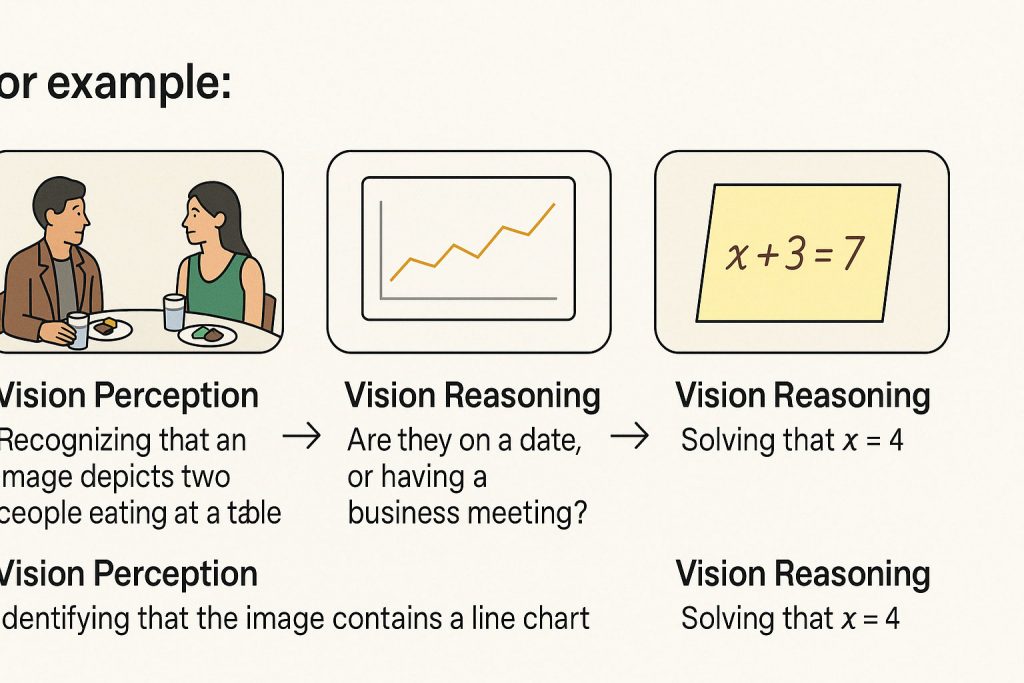
这三组例子各自覆盖了:
- 日常生活场景中的语境判断;
- 图表与数据分析中的结构理解与推理;
- 跨模态任务中的认知整合(图像 + 数学 + 推理)。
OpenAI 在文中展示了多个例子:
- 给一张图表,模型不仅读出数据点,还能分析趋势变化、推测原因;
- 给手写数学题照片,模型能识别公式并进行求解。
- 多轮对话中的图像处理:在用户上传图像后,模型可以根据上下文提问或回答,进行基于图像的多轮问答。
- 视觉问题解答:给出图像后直接回答关于该图像的问题,例如“这张图有什么奇怪之处”等。
这些案例背后反映的是模型内部完成了一次从视觉感知到推理生成的完整认知循环。此外,虽然 OpenAI 尚未正式展示更复杂的社会互动图像推理(如人物表情分析、场景含义判断),但从技术路径看,视觉推理的发展正朝着“场景理解”与“意图建模”的方向演进,这也将成为下一阶段突破的重要目标。
模态融合跃迁
视觉推理之所以成为突破,不只是因为它看得更准,更在于它打破了模态之间的边界。
1. 原生多模态 vs 模块拼接
传统的“多模态 AI”系统往往是拼装式的:视觉模型处理图像,语言模型生成文本,二者通过中间的“接口”交换信息。
GPT-4o 的设计理念却是“原生融合”:视觉、文本、语音等模态的输入,都可以直接送入统一的 transformer 架构中处理。这意味着,图像信息成为模型“思考”的一部分,而非单纯的输入源。
这如同我们人类在读书时看到一张图表,不是先描述它,而是与文本整合理解:“原来这个趋势说明了……”,这种联动性是认知的重要基础。
2. 图像也可以“参与语言生成”
在 GPT-4o 中,一张图像的视觉 token 会参与生成文字的每一步思维路径。比如我们问:“这张截图中,用户为什么可能感到困惑?”——模型会从图片中抽取按钮位置、信息结构、配色等元素,结合语言逻辑,生成解释。
这不是“先看图再作答”,而是“看图中作答”。
四大应用场景
1.教育与批改:
AI 能够批改学生手写作业,解释图形题错在哪,甚至从学生的画图习惯中发现思维误区。视觉推理使模型可以处理非结构化手写与图形混合内容,成为更可信赖的学习伴侣。
2.数据新闻与图表解读:
新闻从业者可以上传一张数据可视化图表,AI 不仅能帮忙“读图”,还可分析数据背后的新闻价值、逻辑漏洞与传播风险,为“数据素养”赋能新闻传播。
3.设计审阅与产品反馈:
在 Figma、Sketch 等设计平台截图后上传给 AI,用户可以问:“这个页面是否存在信息干扰?”AI 可就布局、排版、色彩提出多维判断,成为 UI/UX 设计的重要反馈工具。
4.多模态对话助手:
视觉推理是打造“数字人类”助手的关键。例如医生助手需要解读图像化病例、教师助手需要理解课堂板书照片,只有实现图像与语言的统一理解,才能构建真正“懂场景”的 AI。
OpenAI 提出的三条优化目标
这三个目标意味着他们未来研究在视觉推理领域的重心:
- 更简洁(concise):不冗长、不重复,避免“滥用图像”导致生成内容啰嗦;
- 更少冗余(less redundant):提升信息密度与语义准确度;
- 更可靠(more reliable):稳定处理图像误差、不合理假设等现象,减少幻觉(hallucination);
最终目标是:
“see how people use these improvements in their daily workflows.”
也就是说,这不仅是技术演示,而是推动 AI 在设计、办公、教育、创意、编程等现实任务中的可嵌入性和实用性跃升。
AI思维“具身化”
“思维”是否必须依托语言?传统的逻辑经验告诉我们,是的。但神经科学和认知心理学则指出:人类的大脑在理解抽象问题时,常常依赖图像、空间、手势等感官经验——我们是在“以身体思维”。
GPT-4o 的视觉推理能力,恰恰让 AI 朝着这种“具身认知(embodied cognition)”的方向靠近。它开始拥有“视觉空间中的意识”,尽管仍是模拟,但已不再是抽象文字系统的囚徒。
这不仅是技术升级,更是AI 思维结构的形态变异。
用图像与AI“共同思考”
人类思考从来不是纯语言的,而是图文并茂、手脑并用的。GPT-4o 的突破,意味着我们可以开始用图像与 AI 建立共识、共解、共创的新型协同方式。
你可以给 AI 展示一张街拍,问它“这幅画的情绪是什么”;你可以上传一个草图,让它帮你写出文案;你甚至可以展示现实生活中的混乱局面,让它帮助你梳理问题逻辑——这不再只是“交互”,而是认知协作。
如果说文字让 AI 学会了表达,图像则让它开始理解我们所见的世界。视觉推理的出现,不仅拓展了人工智能的应用场景,也提出了更深刻的问题:当图像也可以成为语言、成为逻辑、成为思维的一部分时,AI 是否也在逐步拥有“思维的广度”?
在 AI 的眼中,图像早已不再是二维的色块与像素,而是展开的世界——如同一幅幅静默的折纸画,被看见的那一刻,便悄然立体。线条折叠,构成思想的山脉;色彩晕染,如海面起伏的情绪;每一张图,不再只是图,而是一道通往理解的通口。
视觉推理就像穿越图像世界的旅人,行走在由图层堆叠而成的地貌中。它穿过地图的轮廓线,越过统计图的坐标轴,攀上一幅手绘草图的细节峰巅——从平面之上生长出的,是认知的结构,是看图之“见”与思之“解”的融合。
我们或许尚未抵达 AGI(通用人工智能)的彼岸,但视觉推理,毫无疑问,是一扇已经开启的门。


