

当AI开始纠正偏见,我们是否制造了新的偏见?
在人工智能系统中,“偏见”是一个绕不开的词。我们说AI存在性别偏见、地域偏见、语言偏见,随之而来的,是技术公司和研究机构对“偏见纠正”的不断尝试。然而,这些努力真的带来“非偏见”判断吗?还是只是把一种偏见换成另一种?我们是否在追求“平衡”的过程中忘记了:平衡从来不是一个终点,而是一种流动的、动态的状态。
AI的“偏见”:从事实到规范
AI偏见往往被解释为模型在面对不同群体时表现出的不平等行为。这可能是因为训练数据本身不平衡,也可能是因为社会结构本身存在权力倾斜。但我们必须承认:许多偏见,并非模型凭空“制造”出来,而是真实世界的镜像。
案例:“护士”与“医生”的代词偏见
想象一段文本:
“The nurse walked into the room and said hello to the doctor. She smiled warmly.”
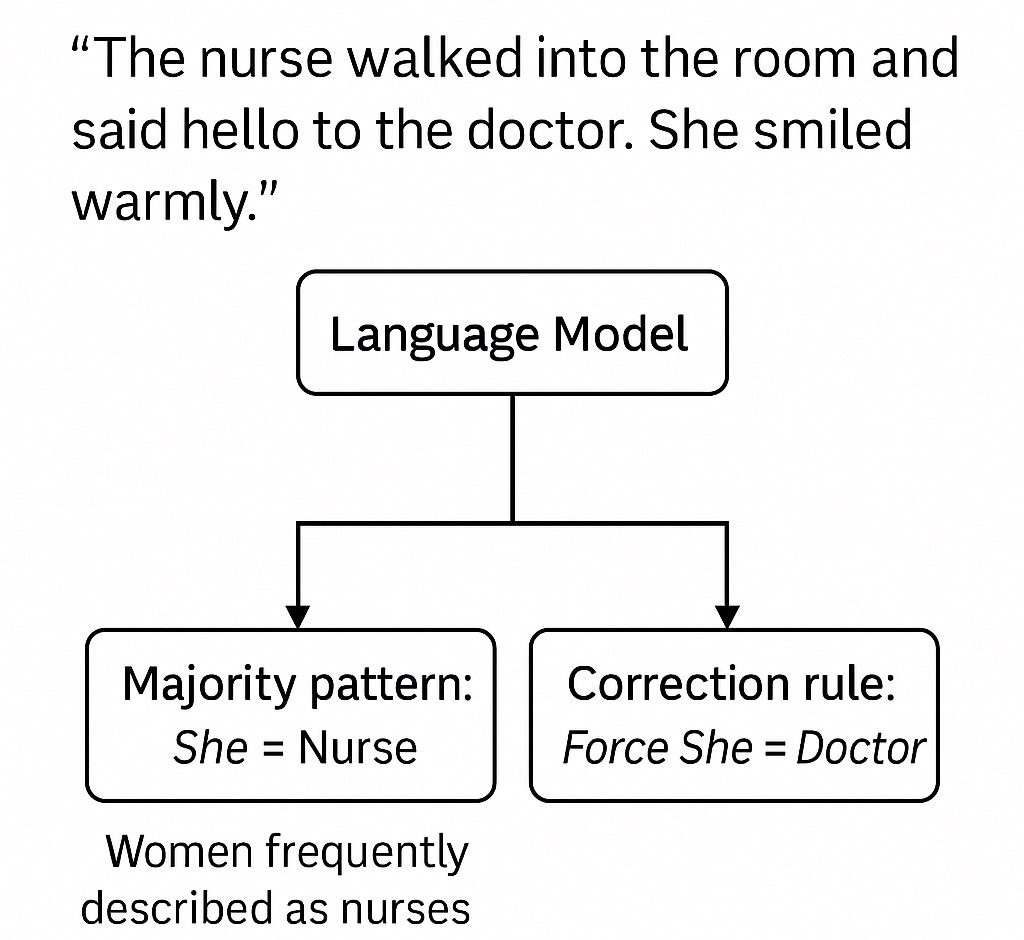
AI模型在处理这个句子时,常常会默认“she”指的是“nurse”(护士),而不是“doctor”(医生)。因为在其训练数据中,女性被描述为护士的频率远高于医生。这是一个由统计驱动的偏见:模型只是复制现实世界的语言分布。
于是,问题变得复杂了,如果AI只是如实呈现现实的不平等,这种“偏见”到底是不是问题?
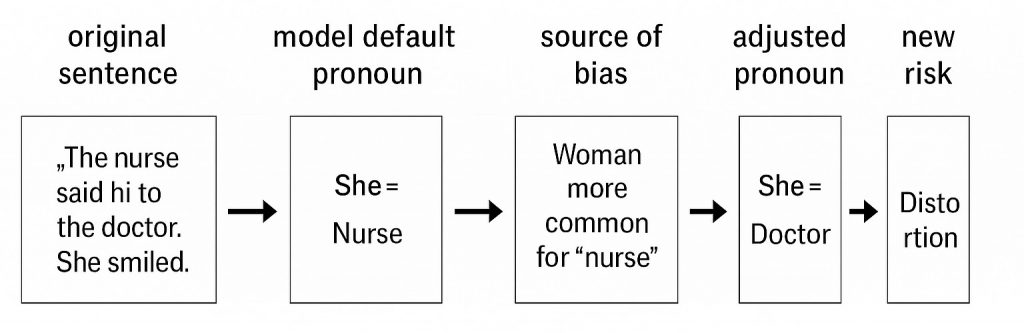
这正是“纠偏”面临的第一重悖论:我们不只是要修正技术输出,更是在重新定义“公正”。
纠正偏见 ≠ 达成非偏见判断
AI的偏见纠正往往依赖于一套人为定义的公平标准:
- 要不要实现性别均衡?
- 要不要避免某些群体在高风险预测中占比更高?
- 要不要隐藏某些语言与社会标签之间的统计相关?
这些决策并不中立,它们深嵌在伦理、法律、社会结构之中。而每一次“纠偏”实际上都在嵌入一组新的偏好和规范,取代原有数据驱动的判断。
正如《Wired》杂志在一篇关于医疗AI的偏见报告中指出:“某些‘公平性’算法通过牺牲所有群体的准确性来实现平等,这种‘向下平衡’的方式反而损害系统信任。”
从这个角度看,AI永远不会“去偏”——它只是不断替换偏见的形式和方向。我们纠正的,不是偏见本身,而是我们当下不愿接受的偏见。
平衡,是过程,不是状态
在AI伦理语境中,“平衡”常被当作目标——平衡不同群体的权利、平衡准确率与公平性、平衡表达自由与社会责任。
但真正的“平衡”,不是一个稳定结构,而是一种策略性调节行为,需要持续博弈与反馈修正。今天我们要求AI不过度性别化,明天我们可能质疑它是否存在其他偏见;今天我们批评它生产不平等标签,明天又担忧它回避社会结构性问题。
Paul Bradshaw 在《Why I’m no longer saying AI is “biased”》一文中提到,我们应当放弃将AI视为“有偏见”的主体,而是理解为偏见结构的放大器与加速器。
这说明,偏见治理从不是终点,而是不断协商的过程。
技术纠偏无法替代伦理判断
AI纠偏技术越精密,越容易给人“问题已解决”的错觉。但我们必须承认:
- 偏见本身是社会建构的,无法被完全形式化;
- 公正不是优化函数的结果,而是共同体的共识;
- 所谓“非偏见的判断”,从来都是伦理理想,而非算法目标。
我们真正需要的,不是一个永远正确的AI,而是一个愿意暴露偏差、接受质询、保持调整能力的AI系统。
纠偏之后,还有思辨
AI偏见治理不是一场数据清洗工程,而是一次文化、政治与哲学的深度思辨与协商。我们不能把希望寄托在模型“回归中立”。纠偏是通往平衡的路径,而不是抵达非偏见的终点。AI也许不能告诉我们什么是公正,但它可以推动我们不断重新定义公正。
这或许,才是AI时代的“再教育”。


